python中的csv+matp的使用案例
csv
如下案例:

分析csv文件头
import csv
filename = 'sitka_weather_07-2014.csv'
# 打开文件并将文件对象存储在f中
with open(filename) as f:
# 调用csv.reader() 传入文件对象 创建一个与该文件相关联的阅读器对象
reader = csv.reader(f)
# csv的reader类包含next方法,调用内置函数next并将reader作为参数传递时,将会调用reader的next方法 从而返回文件的下一行
# 因为只调用了一次next,所以得到的是文件的第一行 结果是一个列表
header_row = next(reader)
print(header_row)最终得到的列表如下:
['AKDT', 'Max TemperatureF', 'Mean TemperatureF', ... ' CloudCover', ' Events', ' WindDirDegrees']打印文件头及其位置
import csv
filename = 'sitka_weather_07-2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
for index, column_header in enumerate(header_row):
print(index, column_header)enumerate(header_row):获取每个元素的索引以及其值。这俩值就是index索引, column_header 对应的值。
执行结果如下:
0 AKDT
1 Max TemperatureF
2 Mean TemperatureF
.....
20 CloudCover
21 Events
22 WindDirDegrees从结果看,日期和最高气温分别存储在第0列和第1列。
提取并存储数据
import csv
filename = 'sitka_weather_07-2014.csv'
with open(filename) as f:
reader = csv.reader(f)
# 获取第一行
header_row = next(reader)
highs = []
# 因为已经读第一行了(next) 阅读器对象会从其停留的地方继续往下读取csv文件
# 每次都自动返回当前所处位置的下一行 由于已经读取的文件头 所以会从文件头的下一行开始
# 所以再遍历就是除第一行外余下的行
for row in reader:
# 因为从csv中读取的数都是 字符串 ['64', '71', '64', '59'..] 要转成整型
high = int(row[1])
# 每次遍历都将索引1处的值加入到highs的末尾
highs.append(high)
print(highs)使用最高的气温数据结合matp绘制一个折线图:
import csv
from matplotlib import pyplot as plt
# 设置支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体字体
# 解决负号显示为方块的问题
plt.rcParams['axes.unicode_minus'] = False
filename = 'sitka_weather_07-2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
highs = []
for row in reader:
high = int(row[1])
highs.append(high)
# 根据数据绘制图形
fig = plt.figure(dpi=128, figsize=(10, 6))
plt.plot(highs, c='red')
# 设置图形格式
plt.title('2024年7月 每日最高气温', fontsize=24)
plt.xlabel('', fontsize=16)
plt.ylabel('温度', fontsize=16)
plt.tick_params(axis='both', which='major', labelsize=16)
plt.show()plt.tick_params()函数用于设置坐标轴刻度的外观和属性,例如刻度线的长度、宽度、颜色,刻度标签的大小、颜色等。plt.tick_params(axis='both', which='major', labelsize=16) 这行代码的作用是同时设置 x 轴和 y 轴主刻度标签的字体大小为 16 磅。
axis该参数用于指定要设置刻度参数的坐标轴,它可以取以下值:
'x':仅设置 x 轴的刻度参数。
'y':仅设置 y 轴的刻度参数。
'both':同时设置 x 轴和 y 轴的刻度参数。
axis='both' 表示同时对 x 轴和 y 轴的刻度进行设置。
which该参数用于指定要设置的刻度类型,它可以取以下值:
'major':仅设置主刻度的参数。主刻度通常是坐标轴上间隔较大的刻度,例如在一个时间轴上,可能每个月的刻度就是主刻度。
'minor':仅设置次刻度的参数。次刻度通常是在主刻度之间更细的刻度,用于提供更精确的参考。
'both':同时设置主刻度和次刻度的参数。
在上述代码中,which='major' 表示只对主刻度进行设置。
labelsize=16 表示将 x 轴和 y 轴主刻度标签的字体大小设置为 16 磅。
plt.figure()
plt.figure()是 Matplotlib 中用于创建一个新的图形窗口(Figure)的函数。在 Matplotlib 的绘图流程中,一个图形窗口(Figure)是最顶层的容器,它可以包含一个或多个子图(Axes),我们可以在这些子图上进行具体的绘图操作。
dpi=128表示将创建的图形的分辨率设置为每英寸 128 个点。例如,当你将这个图形保存为图片时,图片的清晰度会受到dpi值的影响。dpi值越高,图形的分辨率就越高,图像也就越清晰。
figsize是一个元组,用于指定图形的大小,单位是英寸。元组中的第一个元素表示图形的宽度,第二个元素表示图形的高度。figsize=(10, 6)表示将创建的图形的宽度设置为 10 英寸,高度设置为 6 英寸。结合dpi=128,这个图形在水平方向上大约会有10 * 128 = 1280个像素,在垂直方向上大约会有6 * 128 = 768个像素。
fig = plt.figure(dpi=128, figsize=(10, 6))这行代码的作用是创建一个新的图形窗口,该窗口的分辨率为每英寸 128 个点,宽度为 10 英寸,高度为 6 英寸。
datetime
from datetime import datetime
first_date = datetime.strptime('2025-03-17', '%Y-%m-%d')
print(first_date)datetime.strptime(’日期字符串‘,’时间日期格式‘):将日期字符串转换为一个表示日期的对象
| %A | 星期,如monday |
|---|---|
| %B | 月份,january |
| %m | 用数字表示的月份,01-12 |
| %d | 用数字表示的月份中的一天,01-31 |
| %Y | 四位的年份,如2015 |
| %y | 两位的年份,如15 |
| %H | 24小时制的小时数,00-23 |
| %I | 12小时制的小时数,01-12 |
| %p | am或者pm |
| %M | 分钟数,00-59 |
| %S | 秒数,00-61 |
给图表X轴添加日期
import csv
from matplotlib import pyplot as plt
from datetime import datetime
# 设置支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体字体
# 解决负号显示为方块的问题
plt.rcParams['axes.unicode_minus'] = False
filename = 'sitka_weather_07-2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
# 创建两个空列表
dates, highs = [], []
for row in reader:
# 将包含日期字符串的列 转换为日期对象
current_date = datetime.strptime(row[0], "%Y-%m-%d")
dates.append(current_date)
high = int(row[1])
highs.append(high)
# 根据数据绘制图形
fig = plt.figure(dpi=128, figsize=(10, 6))
plt.plot(dates, highs, c='red')
# 设置图形格式
plt.title('2024年7月 每日最高气温', fontsize=24)
plt.xlabel('', fontsize=16)
# 绘制斜的日期标签
fig.autofmt_xdate()
plt.ylabel('温度', fontsize=16)
plt.tick_params(axis='both', which='major', labelsize=16)
plt.show()plt.plot(x, y, ...):是matplotlib.pyplot模块中用于绘制折线图的重要函数,它可以接收多种不同类型的参数,
x:表示 x 轴的数据,通常是一个数组或列表,用于指定每个数据点在 x 轴上的位置。y:表示 y 轴的数据,同样是一个数组或列表,用于指定每个数据点在 y 轴上的位置。x和y的长度必须相同,因为它们是一一对应的。
绘制一整年的温差,并对高低温区间着色
import csv
from datetime import datetime
from matplotlib import pyplot as plt
# 设置支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体字体
# 解决负号显示为方块的问题
plt.rcParams['axes.unicode_minus'] = False
filename = 'sitka_weather_2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
dates, highs, lows = [], [], []
for row in reader:
current_date = datetime.strptime(row[0], '%Y-%m-%d')
dates.append(current_date)
high = int(row[1])
highs.append(high)
low = int(row[3])
lows.append(low)
fig = plt.figure( dpi=128, figsize=(10, 6) )
# 对最高气温画一个图表
plt.plot(dates, highs, c="red")
# 对最低气温也画一个图
plt.plot(dates, lows, c="blue")
# 给区域着色
plt.fill_between(dates, highs, lows, facecolor='blue', alpha=0.1)
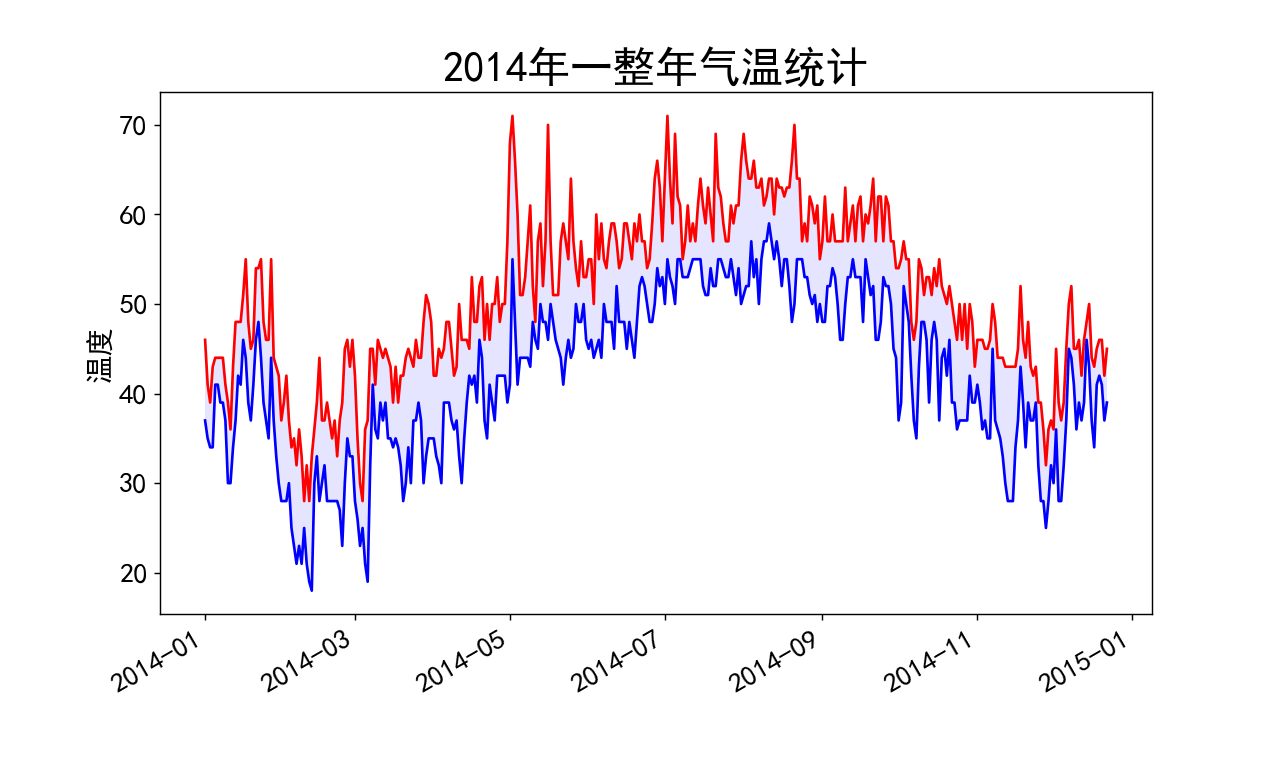
plt.title("2014年一整年气温统计", fontsize=24)
plt.xlabel('', fontsize=16)
fig.autofmt_xdate()
plt.ylabel('温度', fontsize=16)
plt.tick_params(axis='both', which='major', labelsize=16)
plt.show()fill_between(array_x, array_y1, array_y2,facecolor=‘填充的颜色’,alpha=‘填充色的透明度’):
作用:接收一个x值系列和两个Y值系列,并填充两个y值系列之间的空间。这里是使用透明度为0.1的蓝色填充highs和lows之间空间。最终效果如下:
使用try-except-else增加健壮性
我们更换一个有问题的文件,其中数据如下
| PST | Max TemperatureF | Mean TemperatureF | Min TemperatureF | Max Dew PointF | MeanDew PointF | Min DewpointF | Max Humidity | Mean Humidity | Min Humidity | Max Sea Level PressureIn |
| 2014/2/13 | 77 | 56 | 34 | 27 | 23 | 19 | 54 | 32 | 15 | 30.15 |
| 2014/2/14 | 78 | 58 | 37 | 23 | 20 | 17 | 48 | 25 | 13 | 30.12 |
| 2014/2/15 | 82 | 60 | 37 | 20 | 17 | 14 | 39 | 21 | 9 | 30.05 |
| 2014/2/16 |
当我们正常读取处理(上面例子仅仅换文件名)的时候,发现报错如下:
Traceback (most recent call last):
File "D:\python-work\py-bigdata\highs_lows_death.py", line 22, in <module>
high = int(row[1])
^^^^^^^^^^^
ValueError: invalid literal for int() with base 10: ''该traceback指出,PY无法处理其中一天的最高气温,因为它无法将空字符串(' ')转换为整数。
所以我们使用try修改一下,通过捕获错误来不让程序终止运行。
import csv
from datetime import datetime
from matplotlib import pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
filename = 'death_valley_2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
dates, highs, lows = [], [], []
for row in reader:
# 尝试从每一行中提取日期 气温 只要缺失其中一项数据 py就会引发valueError异常
try:
current_date = datetime.strptime(row[0], "%Y-%m-%d")
high = int(row[1])
low = int(row[3])
except ValueError:
# 当出现异常时,打印错误信息 然后循环将继续处理下一行
print(current_date, '数据缺失')
else:
dates.append(current_date)
highs.append(high)
lows.append(low)
fig = plt.figure( dpi=128, figsize=(10, 6) )
plt.plot(dates, highs, c="red")
plt.plot(dates, lows, c="blue")
plt.fill_between(dates, highs, lows, facecolor='blue', alpha=0.1)
plt.title("2014死亡谷年一整年气温统计", fontsize=24)
plt.xlabel('', fontsize=16)
fig.autofmt_xdate()
plt.ylabel('温度', fontsize=16)
plt.tick_params(axis='both', which='major', labelsize=16)
plt.show()这里 只要缺失其中一项数据,就会引发valueError异常,当捕获错误后,循环将接着处理下一行,并不会终止程序的运行。如果获取剩余数据都没有错误,将运行else代码块。
最后控制台打印出只有一个错误数据:
2014-02-16 00:00:00 数据缺失很多数据集都可能缺失数据、数据格式不正确或者数据本身不正确,这种情况,我们可以使用try-except-else或者在某些情况下,需要使用continue来跳过一些数据,或者使用remove()和del将已提取的数据删除。





 目录
目录