浏览器原生的HTML5语音合成功能
功能简介
请先戴上耳机,然后将下面的代码复制到chrome控制台中体验~
let msg = new SpeechSynthesisUtterance("欢迎你阅读我的博客");
window.speechSynthesis.speak(msg);听一下就会发现,播放出来的声音并不是预先录制好的音频资料,而是通过文字识别后合成的语音。
看,前端实现语音合成并不难
今天的主角 Speech Synthesis API
通过上面的例子我们可以猜测到上面调用的两个方法的功能
SpeechSyntehesisUtteranc
window.speechSynthesis.speak当然了,语音合成不仅仅包含这两个API,but我们先从这两点入手。
SpeechSyntehesisUtteranc
SpeechSyntehesisUtteranc()
SpeechSynthesisUtterance.lang
SpeechSynthesisUtterance.pitch
SpeechSynthesisUtterance.rate
SpeechSynthesisUtterance.voice
SpeechSynthesisUtterance.volume注意:以上属性都是 可读写 的! 可以把下面这段代码copy下来尝试一下,注释中会有说明:
let msg = new SpeechSynthesisUtterance();
msg.text = "how are you" // 要合成的文本
msg.lang = "en-US" // 美式英语发音(默认自动选择)
msg.rate = 2 // 二倍速(默认为 1,范围 0.1~10)
msg.pitch = 2 // 高音调(数字越大越尖锐,默认为 1,范围 0~2 )
msg.volume = 0.5 // 音量 0.5 倍(默认为1,范围 0~1)
window.speechSynthesis.speak(msg);同时这个对象还可以响应一系列事件,可能会用到的:
- start
- end
- boundary
- pause
- resume
借助这些事件我们可以完成一些简单的功能,比如英文句子的单词数量统计:
let count = 0; // 词语数量
let msg = new SpeechSynthesisUtterance();
let synth = window.speechSynthesis;
msg.addEventListener('start',()=>{
// 开始阅读
console.log(`文本内容: ${msg.text}`);
console.log("start");
});
msg.addEventListener('end',()=>{
// 阅读结束
console.log("end");
console.log(`文本单词(词语)数量:${count}`);
count = 0;
});
msg.addEventListener('boundary',()=>{
// 统计单词
count++;
});经过尝试,由于中文没有用空格将每个词语分开,所以会进行自动的识别,比如 欢迎读者 会被识别为 欢迎 和 读者 两个词语。
SpeechSynthesis
说完了 SpeechSyntehesisUtteranc 我们再来看看 SpeechSynthesis
SpeechSynthesis 的主要作用是对语音进行一系列的控制,比如开始或者暂停
它有三个只读属性,表明了语音的状态:
SpeechSynthesis.paused
SpeechSynthesis.pending同时还有一系列方法用来操作语音:
•SpeechSynthesis.speak() 开始读语音,同时触发 start 事件
•SpeechSynthesis.pause() 暂停,同时触发 pause 事件
•SpeechSynthesis.resume() 继续,同时触发 resume 事件
•SpeechSynthesis.cancel() 取消阅读,同时触发 end 事件
兼容性以及需要注意的问题
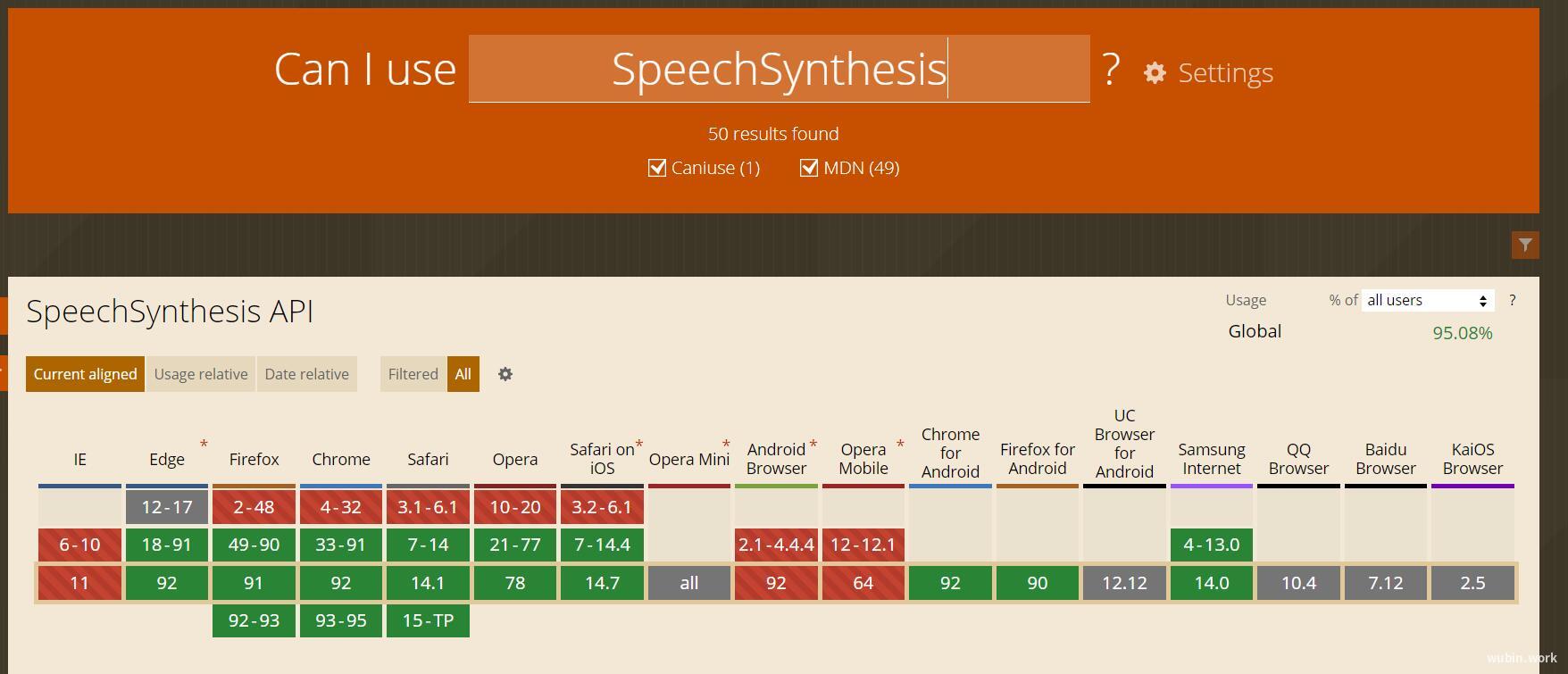
这个特性,是一个还在草案中的特性,没有被广泛支持,再次强调,这个 API 暂时还不能应用到生产环境中。
目前比较通用的做法是在后端构造将文本合成成语音文件的 API(也许是第三方 API),然后在前端作为媒体播放。
可能会遇到的问题
如果直接在浏览器中执行语音播放,可能会失败,并且chrome浏览器会报出提示:

[Deprecation] speechSynthesis.speak() without user activation is no longer allowed since M71, around December 2018. See https://www.chromestatus.com/feature/5687444770914304 for more details
经过查找,最终锁定问题是:自v71版开始禁止语音合成接口自动播放。所以语音合成必须手动进行触发。具体原因请参见《相关链接》
封装一个原生语音合成的类
/**
* 文字转语音,利用H5的新特性SpeechSynthesisUtterance,speechSynthesis实现
* eg.
* const speaker = new Speaker({ text: '这是一条神奇的天路啊' });
* speaker.start(); // 开时播放
// 一秒钟之后暂停,根据实际情况来
* setTimeout(() => { speaker.pause(); }, 1000);
// 两秒秒钟之后暂停,根据实际情况来
* setTimeout(() => { speaker.resume(); }, 2000);
// 三秒钟之后切换内容,根据实际情况来
* setTimeout(() => { speaker.change('我坐上火车就去拉萨,去看那神奇的唐古拉。'); }, 3000);
// 十秒钟之后暂停,根据实际情况来
* setTimeout(() => { speaker.cancel(); }, 10000); // 十秒钟之后暂停,根据实际情况来
*/
class Speaker {
constructor(option) {
const {
lang = 'zh-CN',
pitch = 1,
rate = 1,
volume = 1,
text = ''
} = option;
this.utter = new window.SpeechSynthesisUtterance();
this.utter.lang = lang; // 设置语言环境
this.utter.pitch = pitch; // 设置语音的音调,默认为1
this.utter.rate = rate; // 设置语音的语速,默认为1
this.utter.volume = volume; // 设置语音的音量,0-1之间
this.utter.text = text;
this.getVoices(); // 获取所有声音的集合
}
// 获取当前可用的声音集合
getVoices() {
window.speechSynthesis.onvoiceschanged = () => {
this.voices = window.speechSynthesis.getVoices();
if(this.voices.length > 0) {
this.utter.voice = this.voices[0]; // 设置声音来源
}
};
}
// 开始播放当前的语音
start() {
window.speechSynthesis.speak(this.utter);
}
// 暂停播放
pause() {
window.speechSynthesis.pause();
}
// 暂停之后继续播放
resume() {
window.speechSynthesis.resume();
}
// 清空所有播放
cancel() {
window.speechSynthesis.cancel();
}
// 切换语音的内容
change(text) {
this.utter.text = text;
window.speechSynthesis.speak(this.utter);
}
}// 切记一定要手动触发,语音合成无法自动阅读
playbtn.addEventListener('click', () => {
let content = '青岛是一座美丽的海滨城市';
speaker = new Speaker({ text: content });
speaker.start();
});支持SSML
最近才知道有SSML这个东西,对于它的解释,大家自己搜一下就行。现在要介绍的就是浏览器原生,如何阅读SSML:
var msg = new SpeechSynthesisUtterance();
msg.text ='<?xml version =1.0?> \r\\\< speak version =1.0xmlns =http://www.w3.org/2001/10/synthesisxml:lang =en-US>ABCD< / speak>';
speechSynthesis.speak(msg);还是那个问题,记得要手动的触发阅读加一个点击事件,否则浏览器是不会执行的。
<button id="btn">play</button>
var msg = new SpeechSynthesisUtterance();
msg.text = `
<speak version="1.0" xmlns="https://www.w3.org/2001/10/synthesis" xml:lang="en-US">
<voice name="en-US-ChristopherNeural">
When you're on the freeway, it's a good idea to use a GPS.
</voice>
</speak>
`;
document.getElementById('btn').onclick = function() {
speechSynthesis.speak(msg);
}曾经在我迷茫的时候,我去阅读一些大牛的文章,读到一些前辈对前端开发的思考。其中有一点令我印象深刻:
前端是最贴近用户的,一切要从用户的的角度考虑,无障碍使用也是一个很重要的课题。虽然做这样的功能带来的收益远远小于其他业务,但是为了让产品更好的服务用户,多付出一些劳动也是值得的,这也是前端开发的一种精神。






 目录
目录