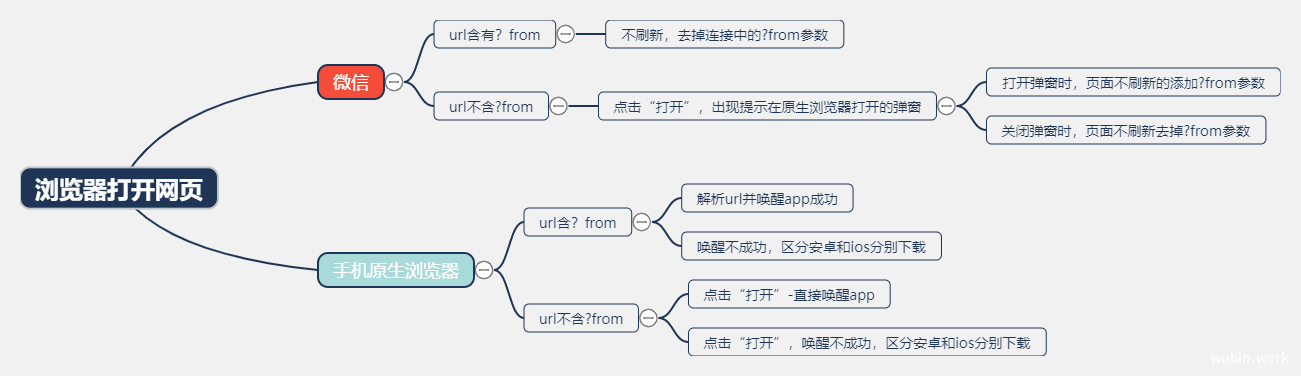
如何使用phpquery?
PHPQuery介绍与安装
require_once 'phpquery/phpQuery/phpQuery.php';gitee下载:https://gitee.com/mirrors/phpquery
简单使用
加载HTML文档
$html = '<html><head><title>PHPQuery Test</title></head><body><h1>Hello PHPQuery!</h1></body></html>';
$doc = phpQuery::newDocumentHTML($html, 'utf-8');使用CSS选择器获取元素
通过使用CSS选择器,可以获取网页中所有符合要求的元素并且在phpQuery对象中进行编辑。
//获取HTML文档中的h1元素
$h1 = $doc->find('h1');注意:此时获得的$h1是一个对象,获取元素建议使用pq。
获取和修改元素属性
phpQuery提供了attr()和removeAttr()方法来获取和移除元素的属性,也支持使用addAttr()和attr()方法来添加和修改元素的属性。
//获取元素的title属性
$title = $h1->attr('title');
//设置元素的title属性
$h1->attr('title', 'PHPQuery Test');
//移除元素的title属性
$h1->removeAttr('title');遍历和复制元素
phpQuery还提供了each()方法来遍历匹配的元素,clone()方法来复制元素。
//遍历所有h5元素
$h5 = $doc->find('h5');
$h5->each(function($index, $element) {
echo $element->tagName . '<br>';
});
//复制元素
$h6 = $h5->clone();网页爬取实例
通过使用以上几个方法,我们可以轻松实现网页爬取。例如,我们想爬取百度首页上的Logo图片。我们可以再次使用find()方法来获取Logo图片元素,并使用attr()方法获取图片的链接地址,最终使用file_gets_content()函数下载该图片。具体代码如下:
//载入百度首页
$html = file_get_contents('https://www.baidu.com');
$doc = phpQuery::newDocumentHTML($html);
//获取百度首页Logo图片链接地址
$img_url = $doc->find('#lg img')->attr('src');
//通过file_get_contents()函数获取图片内容并保存到本地
$img_content = file_get_contents($img_url);
file_put_contents('baidu_logo.jpeg', $img_content);其他示例
<body>
<div class="header"></>
<div class="main"></>
<div class="footer"></>
</body>我要先获取body中所有的元素,然后再删除掉header和footer,那么我该这么操作:
$doc = phpQuery::newDocumentHTML($html, 'utf-8');
$bodyDom = pq("body", $doc);
// 从body中删除.footer和header
pq('.header', $bodyDom)->remove();
pq('.footer', $bodyDom)->remove();
// 获取body的html字符串
$body = $bodyDom->html();其他例子:
<?php
require('phpQuery/phpQuery.php');
// INITIALIZE IT
// phpQuery::newDocumentHTML($markup);
// phpQuery::newDocumentXML();
// phpQuery::newDocumentFileXHTML('test.html');
// phpQuery::newDocumentFilePHP('test.php');
// phpQuery::newDocument('test.xml', 'application/rss+xml');
// this one defaults to text/html in utf8
$doc = phpQuery::newDocument('<div/>');
// FILL IT
// array syntax works like ->find() here
$doc['div']->append('<ul></ul>');
// array set changes inner html
$doc['div ul'] = '<li>1</li> <li>2</li> <li>3</li>';
// MANIPULATE IT
$li = null;
// almost everything can be a chain
$doc['ul > li']
->addClass('my-new-class')
->filter(':last')
->addClass('last-li')
// save it anywhere in the chain
->toReference($li);
// SELECT DOCUMENT
// pq(); is using selected document as default
phpQuery::selectDocument($doc);
// documents are selected when created or by above method
// query all unordered lists in last selected document
$ul = pq('ul')->insertAfter('div');
// ITERATE IT
// all direct LIs from $ul
foreach($ul['> li'] as $li) {
// iteration returns PLAIN dom nodes, NOT phpQuery objects
$tagName = $li->tagName;
$childNodes = $li->childNodes;
// so you NEED to wrap it within phpQuery, using pq();
pq($li)->addClass('my-second-new-class');
}
// PRINT OUTPUT
// 1st way
print phpQuery::getDocument($doc->getDocumentID());
// 2nd way
print phpQuery::getDocument(pq('div')->getDocumentID());
// 3rd way
print pq('div')->getDocument();
// 4th way
print $doc->htmlOuter();
// 5th way
print $doc;
// another...
print $doc['ul'];更详细的说明
加载需要获取内容的网页连接或则文档
主要的常用方法包括:phpQuery::newDocumentFile($file,$contentType = null)$file可以是一个网址地址(带http的)或则html文件路径,如果 $contentType为空,则根据文档自动检测编码。检测失败,则对于text/html类型文档自动赋予utf-8编码。
phpQuery::newDocument($html)<?php
header("Content-Type: text/html;charset=utf-8");
require('phpQuery/phpQuery.php');
/*通过读取URL或则文件路径 返回值是该网站或文件的html,一个网页对应着一个html文件*/
/*eg 1*/
$eg1=phpQuery::newDocumentFile("test.htm");
/*eg 2*/
$eg2=phpQuery::newDocumentFile("http://www.baidu.com");
//可以通过echo htmlentities($eg1,ENT_QUOTES,"UTF-8");查看返回值。注意htmlentities()函数可以输出原始html代码。
/*eg 3*/
//读入html
$html="<div>
<ul>
<li>第一行</li>
<li>第二行</li>
</ul>
</div";
$eg3=phpQuery::newDocument($html);//输入入参数为html
?>phpQuery::newDocument($file)初始加载时返回html的串后,就可以使用html操作句柄函数——pq(),通过pq()来筛选提取指定的内容。
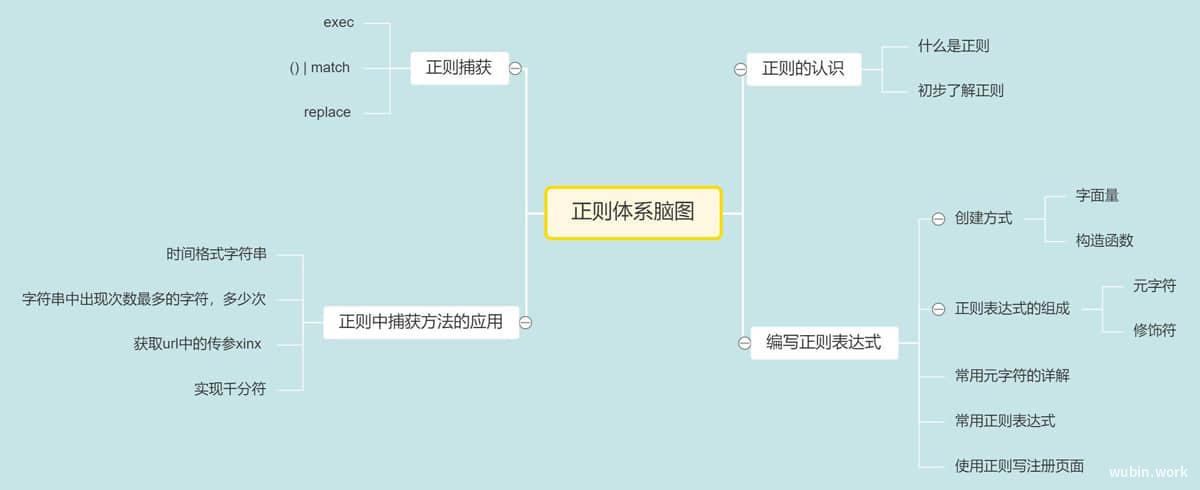
pq()函数用法
pq()函数的用法是phpQuery的重点,pq($xpath,$DocumentID)函数有个参数,第一个$xpath是通过html标签/类/id等定位到某一元素,$DocumentID可以看做为一个指针,指向需要查询的html文档(也就是phpQuery::newDocumentFile($file)的返回结果。
如:$eg1或$eg2或$eg3——其实也就是html的context。当同时对多个文档操作时,需要用到这个参数,如果没有给出,会自动邻近匹配匹配,因此如果只对一个文档操作时,可以省略即使用——pq($xpath)就可以。
pq(); 相当于 jQuery的$()。主要分两部分:即选择器和过滤器。
选择器
- #id 根据给定的ID属性匹配单个元素。
- element 根据给定的名称匹配所有符合的元素。
- .class 根据给定的class匹配所有的元素。
- * 选择所有元素。
- selector1, selector2, selectorN 根据所有制定的选择器匹配结合结果选择结果是取并集
/* 基本选择器*/
1) #id pq("#myDiv");
2) element pq("div");
3) .class pq(".myClass");
4) * pq("*")
5) selector1,selectorN pq("div,span,p.myClass")层次选择器
- parent > child 匹配由父元素指定的子元素指定的所有子元素。
- prev + next 根据指定的”next”和指定的”prev”匹配所有的下一个元素。
- prev ~ siblings 匹配根据”prev” 元素的 所有相邻元素。
- ancestor descendant 匹配由先祖指定的元素的后代指定的所有后代元素。
/* 层次选择器*/
1) ancestor descendant pq("form input")
2) parent > child pq("form > input")
3) prev + next pq("label + input")
4) prev ~ siblings pq("form ~ input")过滤器
- :first 匹配第一个被选择的元素。
- :last 匹配最后一个被选择的元素。
- :not(selector) 匹配所有不是被选择的元素。
- :even 匹配所有被选择的偶数元素,0索引。
- :odd 匹配所有被选择的奇数元素,0索引。
- :eq(index) 匹配等同于给定的索引的元素。
- :gt(index) 匹配大于给定的索引的元素。
- :lt(index) 匹配小于给定的索引的元素。
- :header 匹配所有header元素,如h1,h2,h3等。
- :animated 匹配正在进行动画效果的元素。
/*基础过滤*/
1) :first pq("tr:first")
2) :last pq("tr:last")
3) :not(selector) pq("input:not(:checked)")
4) :even pq("tr:even")
5) :odd pq("tr:odd")
6) :eq(index) pq("tr:eq(1)")
7) :gt(index) pq("tr:gt(0)")
8) :lt(index) pq("tr:lt(2)")
9) :header pq(":header").css("background", "#EEE");内容过滤
- :contains(text) 匹配包含指定文本的元素。
- :empty 匹配所有无子节点的元素(包括文本节点)。
- :has(selector) 匹配至少包含一个对于给定选择器的元素。
- :parent 匹配所有父元素 - 拥有子元素的,包括文本。
/*内容过滤*/
1) :contains(text) pq("div:contains('John')")
2) :empty pq("td:empty")
3) :has(selector) pq("div:has(p)").addClass("test");
4) :parent pq("td:parent")属性过滤
- [attribute] 匹配给定属性的元素。
- [attribute=value] 匹配给定属性等于确定值的元素。
- [attribute!=value] 匹配给定属性不等于确定值的元素。
- [attribute^=value] 匹配给定属性是确定值开始的元素。
- [attribute$=value] 匹配给定属性是确定值结尾的元素。
- [attribute*=value] 匹配给定属性包含确定值的元素。
- [selector1selector2selectorN] 匹配给定属性并且包含确定值的元素。
1) [attribute] pq("div[id]")
2) [attribute=value] pq("input[name='newsletter']").attr("checked", true);
3) [attribute!=value] pq("input[name!='newsletter']").attr("checked", true);
4) [attribute^=value] pq("input[name^='news']")
5) [attribute$=value] pq("input[name$='letter']")
6) [attribute*=value] pq("input[name*='man']")
7) [selector1][selectorN] pq("input[id][name$='man']")子元素过滤
- :nth-child(index/even/odd/equation) 匹配所有是父元素的第n个的子元素,或者是父元素的偶数或者奇数子元素。
- :first-child 匹配所有是父元素的第一个的子元素。
- :last-child 匹配所有是父元素的最后一个的子元素。
- :only-child 匹配所有是父元素唯一子元素的子元素。
1) :nth-child(index/even/odd/equation) pq("ul li:nth-child(2)")
2) :first-child pq("ul li:first-child")
3) :last-child pq("ul li:last-child")
4) :only-child pq("ul li:only-child")基于表单
- :input 匹配input, textarea, select和button元素。
- :text 匹配所有类型为text的input元素。
- :password 匹配所有类型为password的input元素。
- :radio 匹配所有类型为radio的input元素。
- :checkbox 匹配所有类型为checkbox的input元素。
- :submit 匹配所有类型为submit的input元素。
- :image 匹配所有类型为image的input元素。
- :reset 匹配所有类型为reset的input元素。
- :button 匹配所有类型为button的input元素和button元素。
- :file 匹配所有类型为file的input元素。
- :hidden 匹配所有类型为hidden的input元素或者其他hidden元素。
1) :input pq(":input")
2) :text pq(":text")
3) :password pq(":password")
4) :radio pq(":radio")
5) :checkbox pq(":checkbox")
6) :submit pq(":submit")
7) :image pq(":image")
8) :reset pq(":reset")
9) :button pq(":button")
10) :file pq(":file")
11) :hidden pq("tr:hidden")表单过滤
- :enabled 匹配所有可用元素。
- :disabled 匹配所有不可用元素。
- :checked 匹配所有被勾选的元素。
- :selected 匹配所有被选择的元素。
1) :enabled pq("input:enabled")
2) :disabled pq("input:disabled")
3) :checked pq("input:checked")
4) :selected pq("select option:selected")其他方法
attr属性获取
- attr($name) 访问第一个给名称的元素的属性。这个方法可以很轻易地取得第一个匹配到的元素的属性值。如果这个元素没有对应名称的属性则返回undefined。
- attr($properties) 对于所有匹配到的元素设置对应属性。
- attr($key, $value) 对于匹配到的元素设置一个属性和对应值。
- attr($key, $fn) 对于匹配到的元素设置一个属性和需要计算的值。
- removeAttr($name) 对匹配到的元素移除给定名称的属性。
- addClass($class) 对匹配到的元素添加一个给定的类。
- hasClass($class) 如果有至少一个匹配到的元素包含给定的类则返回true。
- removeClass($class) 对匹配到的元素移除给定名称的类。
- toggleClass($class) 对匹配到的元素,如果类不存在则添加,如果存在则移除。
1) attr pq("img")->attr("src");
2) attr(properties) pq("img")->attr({ src: "test.jpg", alt: "Test Image" });
3) attr(key,value) pq("img")->attr("src","test.jpg");
4) attr(key,fn) pq("img")->attr("title", function() { return this.src });
5) removeAttr(name) pq("img")->removeAttr("src");
6) addClass(class) pq("p")->addClass("selected");
7) removeClass(class) pq("p")->removeClass("selected");
8) toggleClass(class) pq("p")->toggleClass("selected");HTML获取
- html() 获取第一个匹配到的元素的html内容(innerHTML)。这个方法不适用于XML文本(但适用于XHTML。)
- html($val) 对匹配到的元素设置html内容。这个方法不适用于XML文本(但适用于XHTML。)
1) html() pq("div")->html();
2) html(val) pq("div")->html("<p>Hello Again</p>");text获取
- text() 获取匹配到的所有元素的文本内容。
- text($val) 对匹配到的所有元素设置文本内容。
1) text() pq("p")->text();
2) text(val) pq("p")->text("<b>Some</b> new text.");Value 获取
- val() 获取匹配到的第一个元素的value属性的值。
- val($val) 对匹配到的元素设置value值。val($val) 所有的Checks, selects, radio buttons, checkboxes,和select options都会设置相应给定的值。
1) val() pq("input")->val();
2) val(val) pq("input")->val("hello world!");其他筛选和文档处理
\*筛选*\
1) eq(index) pq("p")->eq(1)
2) hasClass(class) pq("div")->hasClass("protected")
3) filter(expr) pq("p")->filter(".selected")
4) filter(fn) pq("p")->filter(function($index) {
return pq("ol", pq($index))->size() == 0;
});
5) is(expr) pq("input[type='checkbox']")->parent()->is("form")
6) map(callback) pq("p")->append(pq("input").map(function(){
return pq(this)->val();
})->get()->join(", "));
7) not(expr) pq("p")->not(pq("#selected")[0])
8) slice(start,[end]) pq("p")->slice(0, 1)->wrapInner("<b></b>");
9) add(expr) pq("p")->add("span")
10) children([expr]) pq("div")->children()
11) contents() pq("p")->contents()->not("[@nodeType=1]").wrap("<b/>");
12) find(expr) pq("p")->find("span")
13) next([expr]) pq("p")->next()
14) nextAll([expr]) pq("div:first")->nextAll()->addClass("after");
15) parent([expr]) pq("p")->parent()
16) parents([expr]) pq("span")->parents()
17) prev([expr]) pq("p").prev()
18) prevAll([expr]) pq("div:last")->prevAll()->addClass("before");
19) siblings([expr]) pq("div")->siblings()
20) andSelf() pq("div")->find("p")->andSelf()->addClass("border");
21) end() pq("p")->find("span")->end()
\*文档处理*\
1) append(content) pq("p")->append("<b>Hello</b>");
2) appendTo(content) pq("p")->appendTo("#foo");
3) prepend(content) pq("p")->prepend("<b>Hello</b>");
4) prependTo(content) pq("p")->prependTo("#foo");
5) after(content) pq("p")->after("<b>Hello</b>");
6) before(content) pq("p")->before("<b>Hello</b>");
7) insertAfter(content) pq("p")->insertAfter("#foo");
8) insertBefore(content) pq("p")->insertBefore("#foo");
9) wrap(html) pq("p")->wrap("<div class='wrap'></div>");
10) wrap(elem) pq("p")->wrap(pq("#content"));
11) wrapAll(html) pq("p")->wrapAll("<div></div>");
12) wrapAll(elem) pq("p")->wrapAll(pq("#content"));
13) wrapInner(html) pq("p")->wrapInner("<b></b>");
14) wrapInner(elem) pq("p")->wrapInner(pq(".content"));
15) replaceWith(content) pq("p")->replaceWith("<b>Paragraph. </b>");
16) replaceAll(selector) pq("<b>Paragraph. </b>")->replaceAll("p");
17) empty() pq("p")->empty();
18) remove([expr]) pq("p")->remove();
19) clone() pq("b")->clone()->prependTo("p");
20) clone(true) pq("button")->clone(true)->insertAfter(pq("b"))爬虫综合案例
以武汉大学通知公告http://www.whu.edu.cn/tzgg.htm为例进行爬取测试test.php
<?php
header("Content-Type: text/html;charset=utf-8");
require('phpQuery/phpQuery.php');
$eg1=phpQuery::newDocumentFile("http://www.whu.edu.cn/tzgg.htm");
$eg2=phpQuery::newDocumentFile("https://www.baidu.com/");
echo pq("title",$eg1)->html()."<br>";
echo pq("title",$eg1->getDocumentID())->html()."<br>";//$eg1与$eg1->getDocumentID()效果等同
echo pq("title")->html()."<br>";//就近匹配 $eg2
phpQuery::selectDocument($eg1); //默认会使用选定的文档
echo pq("title")->html()."<br>";
// $mes=pq("ul")->html();//获取所有的ul标签中的html内容
// echo $mes;
// echo "<br>___________________<br>";
// $mes=pq("ul,li")->html();//获取所有的ul以及li标签中的html内容
// echo $mes;
// $t=pq("ul[class='article']")->html();//获取ul class="article"的html内容
// echo $t;
$t=pq("ul[class='article']>li:eq(2)")->html();//获取ul class="article" 下第二个子元素li的html内容
echo $t;
$t=pq("ul[class='article']>li:eq(2)>center>div:eq(1)")->html();
echo $t."<br>";
$t=pq("(ul[class='article']>li:eq(2)>center>div:eq(1))")->html();
echo $t."<br>";
$t=pq("(ul[class='article']>li:eq(3)>div[class='col-xs-12 col-sm-6 col-md-6']>a")->html();
echo $t."<br>";
$t=pq("(ul[class='article']>li:eq(3)>div[class='col-xs-12 col-sm-6 col-md-6']>a")->attr("href");
echo $t."<br>";
?>






 目录
目录